Inside Chinese Pinyin: What 79,000+ Sentences Reveal
I analyzed 79,704 Chinese sentences from Tatoeba to understand which pinyin syllables actually appear in practice. The corpus contains 1,161 unique syllables (there are likely more obscure ones not covered here). Using a Trie data structure to map every syllable, I found patterns in tone distribution, character complexity, and polyphonic pronunciation that differ from what textbooks suggest.
Here’s what the data reveals.
The Trie Structure
A Trie (prefix tree) is a data structure where each path from root to leaf represents a complete string. For pinyin, each node is a single letter, and following a path like h → a → n → 4 gives you the syllable “han4”.
Pinyin syllables form a tree where each letter is a node. Here’s the complete h-branch showing how syllables form from root to terminal nodes:

The h-branch from root to all complete syllables (ha, hao, he, etc.). Dashed lines show other branches.
Explore more:
Level 1 →
Level 2 →
Level 3 →
Full Trie → (hover over nodes for details)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
The Tone Paradox
Neutral tone represents only 2.2% of unique syllables, but 8.4% of actual character usage. Why? Extremely common grammatical particles (的, 了, 吗, 么) are all neutral tone:
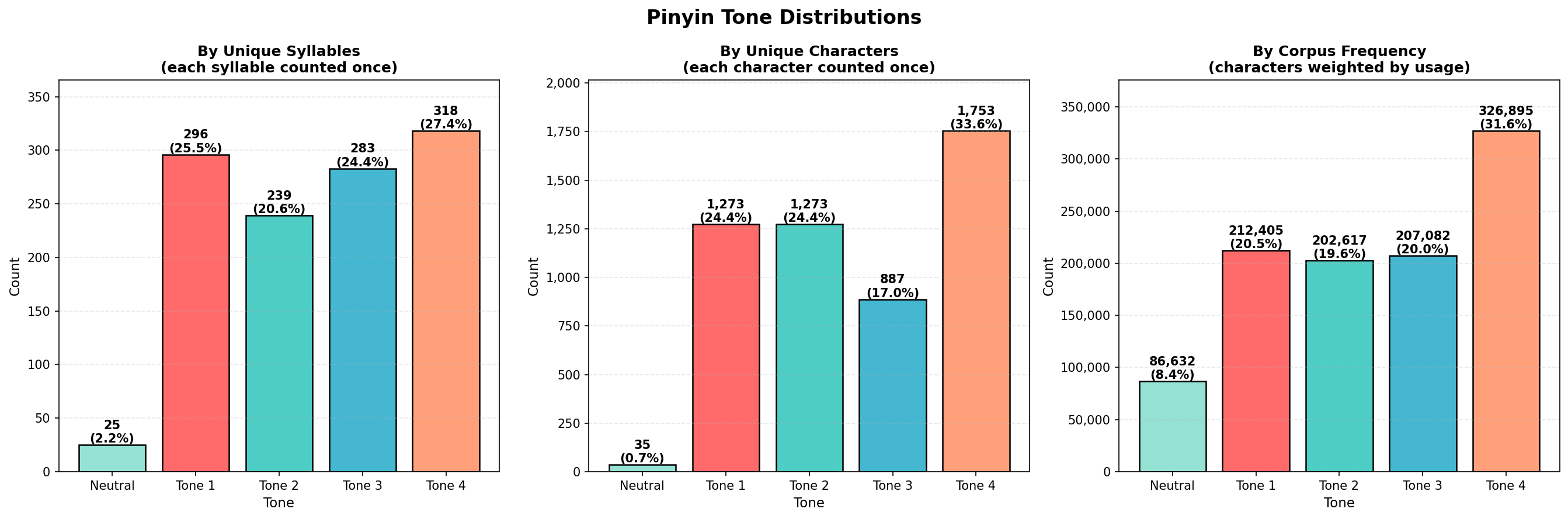 Three perspectives on tone: by syllables, by characters, and by frequency
Three perspectives on tone: by syllables, by characters, and by frequency
Key insight: Tone 4 dominates across all measures (27-34%), while neutral tone punches far above its weight due to particle frequency.
Syllable Crowding
Most pinyin syllables map to a handful of characters. But a few are extremely crowded:
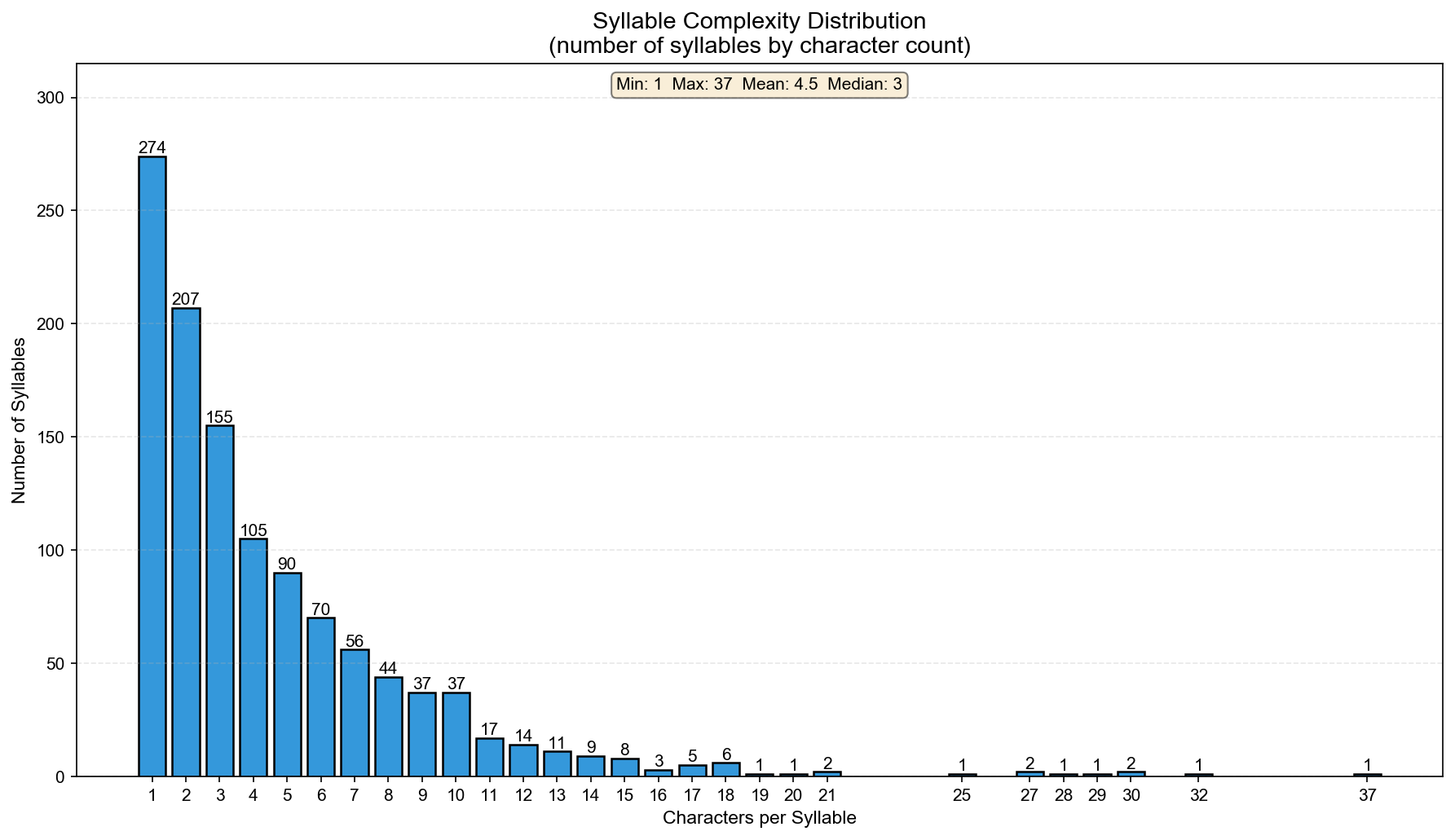 Character count per syllable - most have 3-4 characters, but some have 30+
Character count per syllable - most have 3-4 characters, but some have 30+
The most crowded syllables:
- yi4: 37 characters (意, 义, 议, 异, 易, 亿, 艺, 益…)
- shi4: 32 characters (是, 事, 市, 式, 试, 视, 世, 士…)
- ji4: 30 characters (记, 际, 计, 技, 季, 继, 既, 寄…)
Meanwhile, some syllables are unique to a single character: wo3 (我), le0 (了), ni3 (你).
The Polyphonic Myth
Textbooks emphasize that many Chinese characters have multiple pronunciations. But in the 5,002 characters that appear in this corpus, only 3.8% (199 characters) are actually polyphonic. While Unicode defines 80,000+ Chinese characters, this analysis focuses on what learners encounter in real usage:
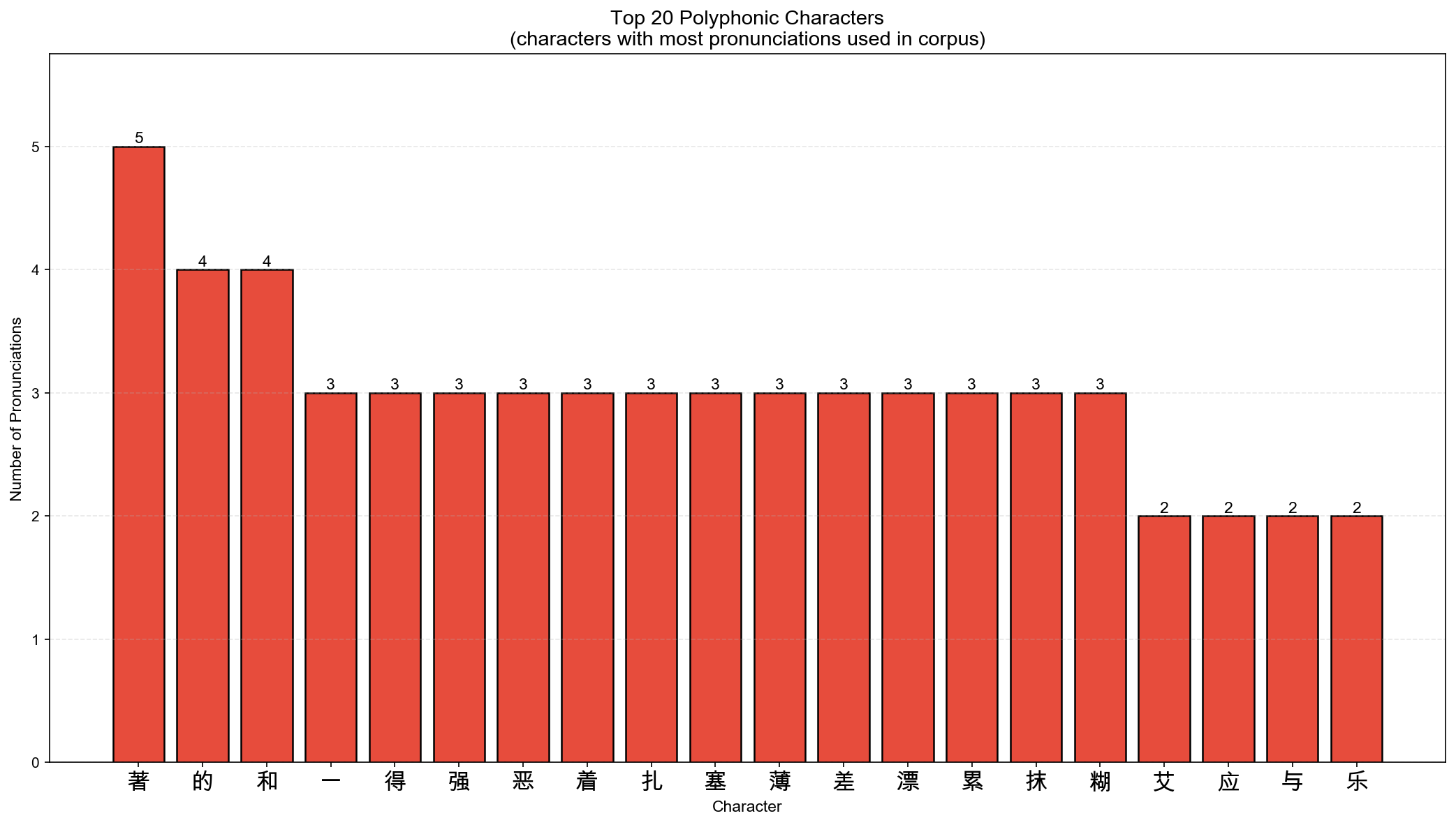 Top 20 characters with multiple pronunciations
Top 20 characters with multiple pronunciations
Even when characters have multiple pronunciations, one usually dominates:
- 的: 4 pronunciations, but
de0is used 99.8% of the time - 一: 3 pronunciations, but
yi1is the primary form - 著: 5 pronunciations (the most polyphonic character in the corpus)
Syllable Structure
Most Chinese syllables complete at depth 4 (3 letters + tone, like ban1 or mao2):
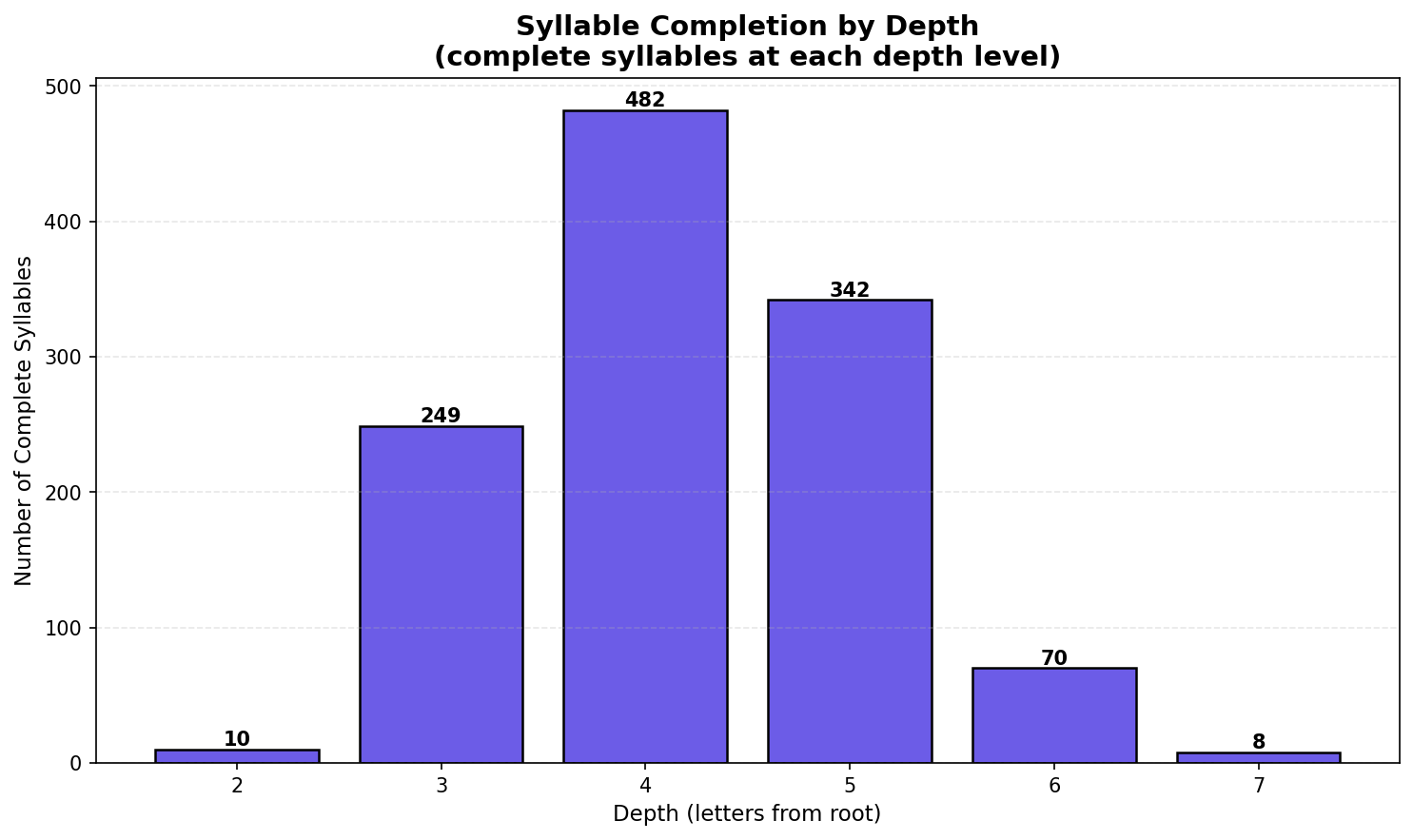 Syllable completion by depth - 41.5% of syllables complete at depth 4 (482 out of 1,161)
Syllable completion by depth - 41.5% of syllables complete at depth 4 (482 out of 1,161)
The longest syllables (depth 7: 6 letters + tone) are all -uang combinations:
- chuang1, chuang2, chuang3, chuang4
- shuang1, shuang3
- zhuang1, zhuang4
Syllable × Tone Coverage
When you strip away tones, 1,161 syllables collapse to 401 base forms. This heatmap shows which base syllables exist across all 5 tones:
 401 base syllables × 5 tones. Cell values show character count. Some bases exist across all tones, others only in one or two.
401 base syllables × 5 tones. Cell values show character count. Some bases exist across all tones, others only in one or two.
Observations:
- Most base syllables don’t have all 5 tone variants
- Neutral tone (column 0) is sparse - only 25 base syllables have it
- Some bases are tone-specific (appear in only 1-2 tone columns)
Key Findings
- 1,161 unique syllables found in 79,704 sentences from the Tatoeba corpus
- 401 base syllables when tones are removed (average 2.9 tones per base)
- 91.8% of characters have only one pronunciation in practice
- Neutral tone: 2.2% of syllables but 8.4% of usage (particle effect)
- Top 10 syllables account for 18.8% of all character instances
- Character homophony: Average 4.5 characters per syllable (range: 1-37)
What You Learned
✓ Chinese has 1,161 unique pinyin syllables (401 base forms without tones)
✓ Only 3.8% of characters in real usage are actually polyphonic
✓ Neutral tone punches above its weight: 2.2% of syllables, 8.4% of usage
✓ Tone 4 dominates across all measures (27-34%)
✓ A Trie data structure maps every syllable path efficiently
Technical Notes
This analysis is based on 79,704 Chinese sentences from the Tatoeba corpus. I built a character-level Trie data structure where each node represents a single letter or tone number, with terminal nodes storing character metadata and frequency data.
Tools: Python 3.9+, matplotlib (charts), graphviz (tree visualization)
Data pipeline:
- Extract characters from corpus
- Compute pinyin with jieba + pypinyin and/or GPT-4o-mini
- Build Trie structure
- Analyze distributions, patterns, and edge cases
Resources
- hanzi-flow on GitHub — Full analysis code and visualizations
- Tatoeba — Sentence corpus